Kubernetes The Hard Way On VirtualBox 2日目
今回やること
前回はノードの作成をしました、今回は接続に必要な証明書の作成です。
Provisioning a CA and Generating TLS Certificates
Public Key Infrastructure (PKI)を準備し、以下のコンポーネントで使うTLS証明書を作成します。
- etcd
- kube-apiserver
- kube-controller-manager
- kube-scheduler
- kubelet
- kube-proxy
PKIてなに?
日本語では「公開鍵暗号基盤」とか訳されて、電子証明書を発行するために用いられ、3つの要素で構成されています。
詳しくは以下を参照して下さい
どこで作業するか
openssl コマンドが使えて、作成した証明書をVMにコピーできる環境であればOK。
公式ではmaster-1ノードを管理用クライアントにする方式が紹介されていますが、私は手元のPCを管理用マシンとして使いたいので手元のPCで行います。
Certificate Authority(認証局)作成
ディレクトリ作成
$ mkdir pki $ cd pki
CA用の秘密鍵作成
$ openssl genrsa -out ca.key 2048
権限問題を回避するために /etc/ssl/openssl.cnf ファイル内の RANDFILE という文字列で始まる行があったらコメントアウトします。
RANDFILEは乱数を生成するためのファイルで、デフォだと $ENV::HOME/.rnd が使われるハズです(多分)
sudo sed -i '0,/RANDFILE/{s/RANDFILE/\#&/}' /etc/ssl/openssl.cnf
openssl req -new -key ca.key -subj "/CN=KUBERNETES-CA" -out ca.csr
自分の秘密鍵を使って自己署名します
$ openssl x509 -req -in ca.csr -signkey ca.key -CAcreateserial -out ca.crt -days 1000 Signature ok subject=CN = KUBERNETES-CA Getting Private key
直下に以下2つのファイルがあることを確認しましょう
ca.crt ca.key
ca.crt はKubernetes認証局の証明書で、ca.key はKubernetes認証局の秘密鍵です。ca.crtは至る所で使われるので色んな所にコピーされます。
ca.keyは認証局が証明書の署名に使います。そしてそれは安全な場所に保管する必要があり、私の環境だと手元のPCが認証局サーバになります。これは他のノードにコピーする必要はありません。
クライアント証明書とサーバ証明書の作成
ここではkubernetesの各コンポーネント用のクライアント証明書とサーバ証明書、adminユーザ用のクライアント証明書を作成します。
admin 用のクライアント証明書作成
admin用の秘密鍵作成
$ openssl genrsa -out admin.key 2048
admin用のCSR作成。OUに注意。adminユーザはsystem:masters グループの一員であることに注意して下さい。
そうすることでkubectlを使ってあらゆる管理操作を行うことが出来ます。
$ openssl req -new -key admin.key -subj "/CN=admin/O=system:masters" -out admin.csr
作成した秘密鍵でadmin用の証明書に署名
$ openssl x509 -req -in admin.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out admin.crt -days 1000 Signature ok subject=CN = admin, O = system:masters Getting CA Private Key
以下のファイルが出来ていることを確認
admin.key admin.crt
admin.keyとadmin.crtがあれば管理者アクセスが可能です。これらをkubectlで使って管理操作を実行できるようにします。
Kubeletのクライアント証明書
ここではスキップします。Workerノードをセットアップする時に行います。
Controller Manager のクライアント証明書
ここではkube-controller-managerのクライアント所証明書と秘密鍵を作成します。
$ openssl genrsa -out kube-controller-manager.key 2048 $ openssl req -new -key kube-controller-manager.key -subj "/CN=system:kube-controller-manager" -out kube-controller-manager.csr $ openssl x509 -req -in kube-controller-manager.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out kube-controller-manager.crt -days 1000
以下のファイルが出来ていることを確認
kube-controller-manager.key kube-controller-manager.crt
Kube Proxyのクライアント証明書
ここではkube-proxy のクライアント所証明書と秘密鍵を作成します。
$ openssl genrsa -out kube-proxy.key 2048 $ openssl req -new -key kube-proxy.key -subj "/CN=system:kube-proxy" -out kube-proxy.csr $ openssl x509 -req -in kube-proxy.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out kube-proxy.crt -days 1000
以下のファイルが出来ていることを確認
kube-proxy.key kube-proxy.crt
Schedulerのクライアント証明書
ここではkube-scheduler のクライアント所証明書と秘密鍵を作成します。
似たような作業が続くのでコピペミスに注意。コピペの乱れは心の乱れ。
$ openssl genrsa -out kube-scheduler.key 2048 $ openssl req -new -key kube-scheduler.key -subj "/CN=system:kube-scheduler" -out kube-scheduler.csr openssl x509 -req -in kube-scheduler.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out kube-scheduler.crt -days 1000
以下のファイルが出来ていることを確認
kube-scheduler.key kube-scheduler.crt
The Kubernetes API Serverの証明書
kube-apiserverの証明書は、アクセス可能なコンポーネント名それぞれに対応するための名前の一部を代替名として持っている必要があります。
maesterサーバ、ロードバランサー、kube-apiサービス等のIPアドレスとDNS名が含まれます。
opensslのconfファイルに以下の設定をします。10.96.0.1はThe Kubernetes API ServerのIPアドレスです。
$ cat > openssl.cnf <<EOF [req] req_extensions = v3_req distinguished_name = req_distinguished_name [req_distinguished_name] [ v3_req ] basicConstraints = CA:FALSE keyUsage = nonRepudiation, digitalSignature, keyEncipherment subjectAltName = @alt_names [alt_names] DNS.1 = kubernetes DNS.2 = kubernetes.default DNS.3 = kubernetes.default.svc DNS.4 = kubernetes.default.svc.cluster.local IP.1 = 10.96.0.1 IP.2 = 192.168.5.11 IP.3 = 192.168.5.12 IP.4 = 192.168.5.30 IP.5 = 127.0.0.1 EOF
kube-apiserverの証明書を作成します
$ openssl genrsa -out kube-apiserver.key 2048 $ openssl req -new -key kube-apiserver.key -subj "/CN=kube-apiserver" -out kube-apiserver.csr -config openssl.cnf $ openssl x509 -req -in kube-apiserver.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out kube-apiserver.crt -extensions v3_req -extfile openssl.cnf -days 1000
以下のファイルが出来ていることを確認
kube-apiserver.crt kube-apiserver.key
ETCDのサーバ証明書作成
kube-apiserverと同様に、etcdにはetcdクラスタを構成する全てのIPアドレスが必要です
$ cat > openssl-etcd.cnf <<EOF [req] req_extensions = v3_req distinguished_name = req_distinguished_name [req_distinguished_name] [ v3_req ] basicConstraints = CA:FALSE keyUsage = nonRepudiation, digitalSignature, keyEncipherment subjectAltName = @alt_names [alt_names] IP.1 = 192.168.5.11 IP.2 = 192.168.5.12 IP.3 = 127.0.0.1 EOF
etcd用の証明書を作成します
$ openssl genrsa -out etcd-server.key 2048 $ openssl req -new -key etcd-server.key -subj "/CN=etcd-server" -out etcd-server.csr -config openssl-etcd.cnf $ openssl x509 -req -in etcd-server.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out etcd-server.crt -extensions v3_req -extfile openssl-etcd.cnf -days 1000
以下のファイルが出来ていることを確認
etcd-server.key etcd-server.crt
Service Accountキーペア
Service Accountキーペアを作成します。
Kubernetesには、User AccountとService Accountがあります。User AccountはEKSではIAMと紐付いたりして、Kubernetesの管理対象ではありません。
Service AccountはPodの実行のために割り当てられ、Namespaceに紐づくリソースです。詳しくはこちらをご覧ください。
Managing Service Accounts | Kubernetes
$ openssl genrsa -out service-account.key 2048 $ openssl req -new -key service-account.key -subj "/CN=service-accounts" -out service-account.csr $ openssl x509 -req -in service-account.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out service-account.crt -days 1000
以下のファイルが出来ていることを確認
service-account.key service-account.crt
証明書の配布
証明書と秘密鍵をコントローラインスタンスに配布します。masterノードからではなく手元のPCで作成した鍵を配布ているので公式とは手順が異なっています
for instance in vagrant@192.168.5.11 vagrant@192.168.5.12 ; do
scp ca.crt ca.key kube-apiserver.key kube-apiserver.crt \
service-account.key service-account.crt \
etcd-server.key etcd-server.crt \
${instance}:~/
done
master-1に配布されているか確認
vagrant@master-1:~$ ll total 116 drwxr-xr-x 5 vagrant vagrant 4096 Sep 23 01:56 ./ drwxr-xr-x 4 root root 4096 Sep 20 05:46 ../ -rw------- 1 vagrant vagrant 680 Sep 22 16:42 .bash_history -rw-r--r-- 1 vagrant vagrant 220 Aug 27 2020 .bash_logout -rw-r--r-- 1 vagrant vagrant 3771 Aug 27 2020 .bashrc drwx------ 2 vagrant vagrant 4096 Sep 20 05:46 .cache/ drwx------ 3 vagrant vagrant 4096 Sep 20 05:46 .gnupg/ -rw-r--r-- 1 vagrant vagrant 807 Aug 27 2020 .profile drwx------ 2 vagrant vagrant 4096 Sep 20 05:46 .ssh/ -rw-rw-r-- 1 vagrant vagrant 1001 Sep 23 01:56 ca.crt -rw------- 1 vagrant vagrant 1679 Sep 23 01:56 ca.key -rwxrwxr-x 1 vagrant vagrant 46007 Sep 20 05:47 cert_verify.sh* -rw-rw-r-- 1 vagrant vagrant 1082 Sep 23 01:56 etcd-server.crt -rw------- 1 vagrant vagrant 1679 Sep 23 01:56 etcd-server.key -rw-rw-r-- 1 vagrant vagrant 1237 Sep 23 01:56 kube-apiserver.crt -rw------- 1 vagrant vagrant 1675 Sep 23 01:56 kube-apiserver.key -rw-rw-r-- 1 vagrant vagrant 1005 Sep 23 01:56 service-account.crt -rw------- 1 vagrant vagrant 1675 Sep 23 01:56 service-account.key
master-2に配布されているか確認
vagrant@master-2:~$ ll total 116 drwxr-xr-x 5 vagrant vagrant 4096 Sep 23 01:56 ./ drwxr-xr-x 4 root root 4096 Sep 20 05:47 ../ -rw------- 1 vagrant vagrant 645 Sep 20 06:23 .bash_history -rw-r--r-- 1 vagrant vagrant 220 Aug 27 2020 .bash_logout -rw-r--r-- 1 vagrant vagrant 3771 Aug 27 2020 .bashrc drwx------ 2 vagrant vagrant 4096 Sep 20 05:47 .cache/ drwx------ 3 vagrant vagrant 4096 Sep 20 05:47 .gnupg/ -rw-r--r-- 1 vagrant vagrant 807 Aug 27 2020 .profile drwx------ 2 vagrant vagrant 4096 Sep 20 05:47 .ssh/ -rw-rw-r-- 1 vagrant vagrant 1001 Sep 23 01:56 ca.crt -rw------- 1 vagrant vagrant 1679 Sep 23 01:56 ca.key -rwxrwxr-x 1 vagrant vagrant 46007 Sep 20 05:48 cert_verify.sh* -rw-rw-r-- 1 vagrant vagrant 1082 Sep 23 01:56 etcd-server.crt -rw------- 1 vagrant vagrant 1679 Sep 23 01:56 etcd-server.key -rw-rw-r-- 1 vagrant vagrant 1237 Sep 23 01:56 kube-apiserver.crt -rw------- 1 vagrant vagrant 1675 Sep 23 01:56 kube-apiserver.key -rw-rw-r-- 1 vagrant vagrant 1005 Sep 23 01:56 service-account.crt -rw------- 1 vagrant vagrant 1675 Sep 23 01:56 service-account.key
今回はここまで!
お読みいただきありがとうございました!
面倒くさかったー
Kubernetes The Hard Way On VirtualBox 1日目
どうした
前からうすうす感じてたんですけど、私はkubernetesを雰囲気で使ってます。
どっかから落としたyamlをイジってはdeploy、既存のyamlをイジってはdeploy
「壊れたら再作成すればいいっしょw」
。。。
なんすかこれ?
なんなんすかこれ?
経典として買ったkubernetes完全ガイドが泣いてました
というわけで再入門。なんとなくスルーしてきた『Kubernetes The Hard Way』をやります!
しかもVirtualBoxでも出来るように神が作ってくれた『Kubernetes The Hard Way On VirtualBox』だッ!
Kubernetes The Hard Way On VirtualBox
本来はGCP上に作成したVMにkubernetesを作成するんですが、これは手元のVirtualBoxで作成したVMにkubernetesを作成します。
結構長いので、地道にやっていこうと思ってます。
今回は1日目。環境構築。
Prerequisites
VM Hardware Requirements
HW要件としては
8 GB of RAM (Preferably 16 GB) 50 GB Disk space
とされてます
私のうちのPCを確認
$ df -h Filesystem Size Used Avail Use% Mounted on udev 32G 0 32G 0% /dev tmpfs 6.3G 2.5M 6.3G 1% /run /dev/nvme0n1p2 457G 180G 254G 42% / tmpfs 32G 235M 32G 1% /dev/shm tmpfs 5.0M 4.0K 5.0M 1% /run/lock
$ free -h
total used free shared buff/cache available
Mem: 62Gi 9.2Gi 29Gi 449Mi 23Gi 52Gi
Swap: 2.0Gi 0B 2.0Gi
余裕っすねうんうん。
Virtual Box
OSのバージョン確認
$ cat /etc/issue Ubuntu 20.04.3 LTS
Virtual Boxのバージョン確認
$ VBoxManage -v 6.1.26r145957
Vagrant
Vagrantのバージョン確認
$ vagrant version Installed Version: 2.2.6 Vagrant was unable to check for the latest version of Vagrant. Please check manually at https://www.vagrantup.com
Provisioning Compute Resources
リポジトリをローカルにcloneします
$ git clone https://github.com/mmumshad/kubernetes-the-hard-way.git
$ cd kubernetes-the-hard-way\vagrant
ここにあるVagrantfileを実行すると、以下のような5つのVMが作成されます。
| VM | VM Name | Purpose | IP | Forwarded Port |
|---|---|---|---|---|
| master-1 | kubernetes-ha-master-1 | Master | 192.168.5.11 | 2711 |
| master-2 | kubernetes-ha-master-2 | Master | 192.168.5.12 | 2712 |
| worker-1 | kubernetes-ha-worker-1 | Worker | 192.168.5.21 | 2721 |
| worker-2 | kubernetes-ha-worker-2 | Worker | 192.168.5.22 | 2722 |
| loadbalancer | kubernetes-ha-lb | LoadBalancer | 192.168.5.30 | 2730 |
$ vagrant up
しばらく待ちましょう。
プロンプトが戻ってきたらVMを確認
$ vagrant status Current machine states: master-1 running (virtualbox) master-2 running (virtualbox) loadbalancer running (virtualbox) worker-1 running (virtualbox) worker-2 running (virtualbox) This environment represents multiple VMs. The VMs are all listed above with their current state. For more information about a specific VM, run `vagrant status NAME`.
$ vagrant ssh master-1 $ vagrant ssh master-2 $ vagrant ssh loadbalancer $ vagrant ssh worker-1 $ vagrant ssh worker-2
workerでは、dokerのバージョン確認も確認しておきましょう
$ sudo docker version Client: Docker Engine - Community Version: 20.10.8 API version: 1.41 Go version: go1.16.6 Git commit: 3967b7d Built: Fri Jul 30 19:54:08 2021 OS/Arch: linux/amd64 Context: default Experimental: true Server: Docker Engine - Community Engine: Version: 20.10.8 API version: 1.41 (minimum version 1.12) Go version: go1.16.6 Git commit: 75249d8 Built: Fri Jul 30 19:52:16 2021 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.4.9 GitCommit: e25210fe30a0a703442421b0f60afac609f950a3 runc: Version: 1.0.1 GitCommit: v1.0.1-0-g4144b63 docker-init: Version: 0.19.0 GitCommit: de40ad0
Installing the Client Tools
管理タスク実行のための公開鍵設定と、kubectlといったクライアントツールを入れます。
master-1に入れる手順が公開されているが私のPCはUbuntuなので、ローカルで公開鍵を発行して書くServerに接続できるようにする
ローカルで鍵発行
$ ssh-keygen
基本的に全てデフォルトでおk
作成した鍵の中身をどこかにコピー
$ cat .ssh/id_rsa.pub
先程作成した全てのVMに鍵をコピー
cat >> ~/.ssh/authorized_keys <<EOF ssh-rsa AAAAB3NzaC1yc2EAAAADA..........E= kbys@pc EOF
Install kubectl
私のPCのはすでに入ってるので、ここら辺を参考にしてください
バージョン確認
$ kubectl version --client
Client Version: version.Info{Major:"1", Minor:"19", GitVersion:"v1.19.2", GitCommit:"f5743093fd1c663cb0cbc89748f730662345d44d", GitTreeState:"clean", BuildDate:"2020-09-16T13:41:02Z", GoVersion:"go1.15", Compiler:"gc", Platform:"linux/amd64"}
今日はここまで!
お読みいただきありがとうございました!
転職して半年経ったよ
TL;DR
退職エントリではなく、入社エントリです。
9月1日でちょうど入社6ヶ月。多少落ち着いてきたので現況を書きたいと思います。
どんな会社?
株式会社スタンバイという、求人検索エンジンを開発・提供している会社です。
こちらがサービスサイトです。
なんで入ろうと思ったの?
以下が主な理由です。とどめは最終面接をしてもらった南社長の熱量に圧倒されました。
- ビジネスの中心にプロダクトがある
- これから発展させていこうというフェーズ
- トラフィックなどのYahooが持っている資産(検索トラフィックとか)を使ってチャレンジが出来る
- 会社自体は設立して2年だがプロダクトはそれ以前からあり実績がある(博打要素が少ない)
最後の部分を解説しますと、「スタンバイ」という仕事検索サービス自体は、2015年に生まれました。このときはビズリーチ内の1事業という位置づけです。
そして2019年に、Zホールディングス株式会社と株式会社ビズリーチは、求人検索エンジン事業を運営する合弁事業会社「株式会社スタンバイ」を設立しました。(公式発表)
そこで何やってるの?
ProductPlatformグループというグループに所属してて、やってることは所謂SREです。
- 各機能のSLOを策定し、SLOを意識した開発をするように啓蒙活動
- EKSとそれに付随するエコシステム(ArgoCD,AppMesh,etc...)の導入
みたいな感じで、あとは各チームのインフラレイヤの相談事に乗ったり、メンテナンスをやったりしてます。
入ってみてどう?
良かったこと
嫌な奴が居なく、心理的安全性が高い。
これは素晴らしいことです。
前に居た会社もそうだったんですけど、みんな常にポジティブで建設的な議論を心がけています。
『会議室の長机の上で土下座させられる』『他の協力会社を潰すために無茶なタスクをやらせる』みたいな世界線で20〜30代を生きてきた私には奇跡のように見えてます。
さらに、現在弊社には大きく分けて
のような、様々な人達が居ます。これだけ見ると『派閥とかあるんちゃうか?』と思うかもしれませんが、全くそんな事ありません。
それぞれが独自のやり方を押し付けるわけでもなく、『どうすればスタンバイというサービスが良くなるのか』について常に議論し、チャレンジし続けている姿には感銘を受けました。
チャレンジしたいこと
完全に私個人の問題ですが、私の悪い癖として『他人がやってる OR やろうとしてるタスクには手を付けない』というのがあります。
要するに誰かとタスクがバッティングしそうになると『どうぞどうぞ。やってみなはれ』とサッと手を引いちゃうんですよね。
また開発スタイルとして、1週間を1スプリントとしたスクラム開発を基本としているので『俺のせいで遅延が発生したらどうしよう』と勝手に遠慮しちゃう性格でもあります。
PO(プロダクトオーナ)は『不慣れな部分はカバーするから、ドンドンチャレンジしてくれ』と言ってくれてるのですが、僕が完全に『どうぞどうぞ型』の人間なのでここは是正して、自分の仕事の幅を広げていきたいところです。
プライベートへの影響
仕事は基本的にフルリモートです。コロナ終息後の対応は未確定ですが、フル出勤に戻ることはなさそうです。
最近はオンライベントの運営に参加し、(ほぼ無力に近いですが)持てる力をイベント成功に注いでいます。
最後に運営に参加しているイベントを2つ紹介させて下さい。
CI/CD Conference 2021
来たる9/3(金)に始まるのが、CI/CD Conference 2021というイベントで、CI/CDに関する勉強会です。
講演を聞くだけではなく、登壇者に質問したり参加者同士で意見を交換できる場所を用意した、双方向なイベントを目指しております。
基本的に講演動画のアーカイブ視聴は可能なので、後からゆっくり見ることも可能です。
参加は無料で、イベント自体は初級者から上級者まで、幅広く対応しています。
こちらから是非登録して下さい!
CloudNative Days Tokyo 2021
こちらは現在登壇者を募集しております。
クラウドを使って組織を変えた、変えようとした、そんな皆さんの知識や経験を共有する交差点となるような場所を目指しております。
登壇したいという方は是非こちらから登録して下さい!
最後までお読み頂き有難うございました。
Rancher Academy Week 3
なんの記事?
これは以前に入学したRancher AcademyのWeek 3の自分用メモです。
Week 3: Deployng Kubernetes With Rancher
-
- Hosted / Infrastructure Provider
- EKS, AKS, GKEなんかに対応してるぞ
- RancherのUIからノードの管理追加といった、ライフサイクル管理ができるぞ
- Custom Provider
- Imported Clusters
制限のあるクラスタについて
- Rancherやk8s自体に制限があるわけではない
- Rancherがインフラレイヤやデータプレーンへのアクセスを制限されてると起きる
- RKEで動いてるインフラやカスタムクラスタは両方共Rancherで管理可能だよ
- ホストされたクラスタはライフサイクルマネジメントを組み込まれてて、Rancherはデータプレーンやコントロールプレンにアクセスできないので、バックアップやリストアをRancherから出来ないんだ
- ImportしたクラスタはRancherには不透明に見えて、バックアップやリストアは組み込まれない
- 非RKEクラスタを使うときは、クラスタの事業継続のためにプロバイダのツールを使う必要があるよ
サイジングについて
- コントロールプレーン、データプレーン、ワーカーロールを別のノードプールに配置すると、リソース食い合わないのでおすすめだよ
- ワークロードにはCPUとメモリの上限を設定してデプロイしてね
障害への心得Rancher Docs: Troubleshooting
- すべての問題には解決策があります。これを覚えていれば、あなたのフラストレーションを軽減し、問題解決に費やすエネルギーを残すことができます。
- 第二の目は、あなたには見えないものを見ることができます。もしあなたが10分、15分以上問題を見ていたら、他の人に一緒に見てもらうように頼んでみてください。彼らがすぐに解決策を見つけてくれることに驚くことでしょう。
- 以前はうまくいっていたことが、今はうまくいかない場合は、「何が変わったのか」と自問してみましょう。どんなに小さなことでも、すべてを考えてみましょう。それらの変更を見直し、それを元に戻すことで問題が解決するかどうかを確認してください。
- 一度に一つのことを変更してからテストする。複数のものを変更して問題が解決した場合、どのものが原因なのか、解決策なのかわからなくなってしまいます。一度に1つのことだけを変更するとき、それはあなたが最初の場所で問題を作成した要因を特定するのに役立ちます。
- 問題は自力では消えない。問題は、それが到着したように神秘的なように消えた場合、それはちょうど神秘的なように返すことができることを知っています。クラスタの最新の状態に「何が変わったのか」という質問を適用して、その原因を見つけようとし続けてください - 問題がなくなるために何が変わったのでしょうか? 問題が発生したときに何かが変わったのでしょうか?
- 問題を客観的に見ることができなくなった、つまり、イライラしたり、怒ったり、感情的になったりしているのであれば、休んでみましょう。帰ってきてからの方が、離れている時間よりも問題解決の効果が高くなります。椅子から立ち上がって、部屋の中を動き回る。深呼吸をする。リラックスしてください。このリストの最初の項目を覚えておいてください - 解決策はそこにあります。多くの場合、外を歩いたり、ブロックの周りを散歩に行くような単純なあなたの環境の変化は、問題を解決する方法についての新しいアイデアをトリガするのに十分です。
Rancher Academy Week 2
なんの記事?
これは以前に入学したRancher AcademyのWeek 2の自分用メモです。
Week 2: Installing and Managing Rancher
- Rancher Server のデプロイ
Standalone構成の場合
- dockerでインストール
docker run -d --restart=unless-stopped \ -p 80:80 -p 443:443 \ --privileged \ rancher/rancher:latest
- バックアップしたい場合は、
/var/lib/rancher内部を保存すると良いぞ Rancherのアップグレード
- Rancher止める
- データコンテナを作成
/var/lib/rancherをバックアップ- 新しいイメージをPULL
- Racher起動
- 動作確認
- 古いRancherコンテナを消す
HA構成の場合
Rancherはk8s内で動くアプリケーションだ
RKEにデプロイする場合
- LB配下に置く場合はL4ロードバランサにしてくれ。SSLターミネートするような構成は非推奨なんだ。
- Helmでデプロイする方法を使うよ(helm repo add rancher-latest https://releases.rancher.com/server-charts/latest)
- 証明書はBYOD、LetsEncrypt、自己証明から選べるよ
Rancher Academy Week 1
なんの記事?
これは以前に入学したRancher AcademyのWeek 1の自分用メモです。
Week 1: Intro to Rancher and RKE
- RancherにはRKEとK3Sという、2つのk8sディストリがあるよ
RKEはRancher Kubernetes Engineの略で、k8sをdockerコンテナで実行するよ
Rancher Serverの構成について
Rancher(管理する方の環境)のInstallには、サンドボックス用に適したスタンドアロン方法と高可用性のk8sクラスタに入れる二つの方法があるよ
RKEのインストール(公式手順)
wget -P /usr/local/bin/ https://github.com/rancher/rke/releases/download/v1.1.0/rke_linux-amd64 sudo mv /usr/local/bin/rke_linux-amd64 /usr/local/bin/rke sudo chmod +x /usr/local/bin/rke rke --version
vmの用意
- dockerが入ったssh接続できるLinuxが必要
- dockerをインストールするスクリプト用意してるよ(https://rancher.com/docs/rancher/v2.x/en/installation/requirements/installing-docker/)
- dockerが入ったssh接続できるLinuxが必要
vm用意して
rke configで接続情報とかを設定して、rke upすればOKだ *成功したら、自動で作られるconfigを移すといいよ
cp kube_config_cluster.yml ~/.kube/config
- RKEの運用について
- kube_config_cluster.yml のオリジナルは保存しておくこと
- デフォルトでは、6時間ごとにスナップショットを作成し、1日分のスナップショットを保持するように設定されてるよ
/opt/rke/etcd-snapshotsに作成されるよ- configで設定を変更することができるよ
- S3や外部ディスクに保存もできるよ
- リストア方法は(Rancher Docs: Restoring from Backup)
- kubernetes自体の更新も簡単にできるぞ(Rancher Docs: Upgrades)
- nodeの追加もyamlに定義を追加して
rke upするだけだ!いいだろ?
Oracle Cloud 監視入門
- コレはなんの記事?
- お前誰よ
- 今回の監視対象
- 監視システムを作ろう
- まとめ
コレはなんの記事?
この記事は、JPOUG Advent Calendar 2020 - Adventar の18日目の記事です。
17日目はおおの たかしさんの記事『Oracle Databaseバージョンアップ後の性能劣化で試したい暫定対処 | アシスト』でした。
私もかつては OracleDBA だった時代があり、サポートには大変お世話になりました。 ただ、『『サポートからの回答待ちです』一辺倒だけではなく、自分でも調査・仮説検証が出来るエンジニアになれ』と先輩によく言われました。
そんなエンジニアになるためのヒントとして素晴らしい記事でした。
今回私がお伝えしたいのは DB から打って変わって、Oracle Cloud 上に作った Web システムを監視することになった場合、
- まず、どこから見れば良いのか
- どうやって見れば良いのか
という事を実例を交えて紹介していきたいと思います。
お前誰よ
現在、株式会社ウィルゲートでインフラエンジニアとして、自社サービスのインフラ運用をメインに日々ぼんやりしてます。
色々な組織形態があるかと思いますが、私は主にインフラの人≒運用の人な世界線で生きてきました。
最近社内勉強会用に書いたこちらの資料の評判が良かったので、
今回は調子に乗って Oracle Cloud 上の Web システム監視のチュートリアルを書きたいと思います。
これからクラウド上に作ったシステムの監視を始めたい方への、何かの参考になれば幸いです。
今回の監視対象
監視対象のシステム構成
Oracle Cloud には Always Free というサービスがありましてですね、なんと
- 2つのOracle Cloud Infrastructure Compute VM、ブロック・ストレージ、オブジェクト・ストレージ、アーカイブ・ストレージ、ロード・バランサとデータ・エグレス、監視と通知
- Oracle Application Express(APEX)やOracle SQL Developerなどの強力なツールを含む、2つのOracle Autonomous Database
がずっと無償で提供されます!
今回ももちろんその範囲内で構成しております。全て Oracle Cloud 上に構築した Web システムです。
ロードバランサ(以下 LB )と、仮想マシン(以下 VM )が1つずつのシンプルな構成です。

VM には NGINX と php-fpm を入れて、以下のような php を置いております。
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>テストサイト</title> </head> <body> <font size="7" color="#00ff00"> <?php $text = array( "おすぎです!", "ピーコです!", ); $count = count($text); $random = rand(0, $count - 1); echo $text[$random]; ?> </font> </html>
さらにはちゃんとドメインをとって、外部公開しています。
アクセスするたびに自分がおすぎなのかピーコなのかを再確認できるサイトなんですが、今年中には閉鎖します。
Oracle Cloud エージェント
Oracle Cloud の VM には、作成時に Oracle Cloud エージェント を有効にしています。
以下の画面にチェックを入れるだけでエージェントがインストールされて、OSの詳細なメトリクスを確認することが出来ます。

実際にOSにログインして確認してみると、 oracle-cloud-agent というサービスの起動を確認できます。
[opc@osugi ~]$ systemctl status oracle-cloud-agent
● oracle-cloud-agent.service - Oracle Cloud Infrastructure agent for management and monitoring
Loaded: loaded (/etc/systemd/system/oracle-cloud-agent.service; enabled; vendor preset: disabled)
Active: active (running) since 日 2020-12-06 01:32:46 GMT; 2min 32s ago
Docs: https://docs.cloud.oracle.com/iaas/
Main PID: 1776 (agent)
CGroup: /system.slice/oracle-cloud-agent.service
├─1776 /usr/libexec/oracle-cloud-agent/agent
├─1808 /usr/libexec/oracle-cloud-agent/plugins/bastions
└─1830 /usr/libexec/oracle-cloud-agent/plugins/gomon/gomon
12月 06 01:32:46 osugi systemd[1]: Started Oracle Cloud Infrastructure age...g.
12月 06 01:32:46 osugi agent[1776]: 2020/12/06 01:32:46 osName:CentOS Linu...:7
12月 06 01:32:46 osugi agent[1776]: 2020/12/06 01:32:46.618165 logger.go:3...og
12月 06 01:32:48 osugi sudo[1845]: oracle-cloud-agent : TTY=unknown ; PWD=...nd
Hint: Some lines were ellipsized, use -l to show in full.
監視システムを作ろう
どこから監視したらいいのか
監視対象のシステムは出来ました。では監視しましょう!
とはいえ、「どこから監視したら良いのか」と悩む方も少なくないでしょう。
そういう場合はまず
- そのシステムの利用者は誰なのか
- 利用者から見て「正常に動いてる状態」とはどういう状態か
を考えましょう。
今回は世界に向けた Web システムなので、『利用者は世界中の人』です。
その人達から見て正常に動いてる状態は、『Web アクセスが正常に行えるか』です。
かといって世界中の人に監視をお願いするわけにもいきません。
そこで外形監視ツールの登場です。
システムの外部(今回だと oracle cloud の外側のネットワーク)から Web アクセスをし、
を定期的にチェックしします。
今回外形監視に使うツールは、site24x7 を使います。
無償プランでも5サイトまで外形監視をすることが出来ます。
必要最低限の監視ならコレで十分かもしれません。
しかし今回の構成で言うと、LB を監視することで
- 実際にどのくらいのアクセスが来てるのか
- 来たアクセスを正常に、遅滞なく処理できているか
ということを確認でき、さらに VM を監視することで
- システムリソースを使い切っていないか
- サーバの I/O が処理待ちになっていないか
を確認することが出来ます。
Oracle Cloud のコンソール画面で LB や VM のメトリクスを確認できます。
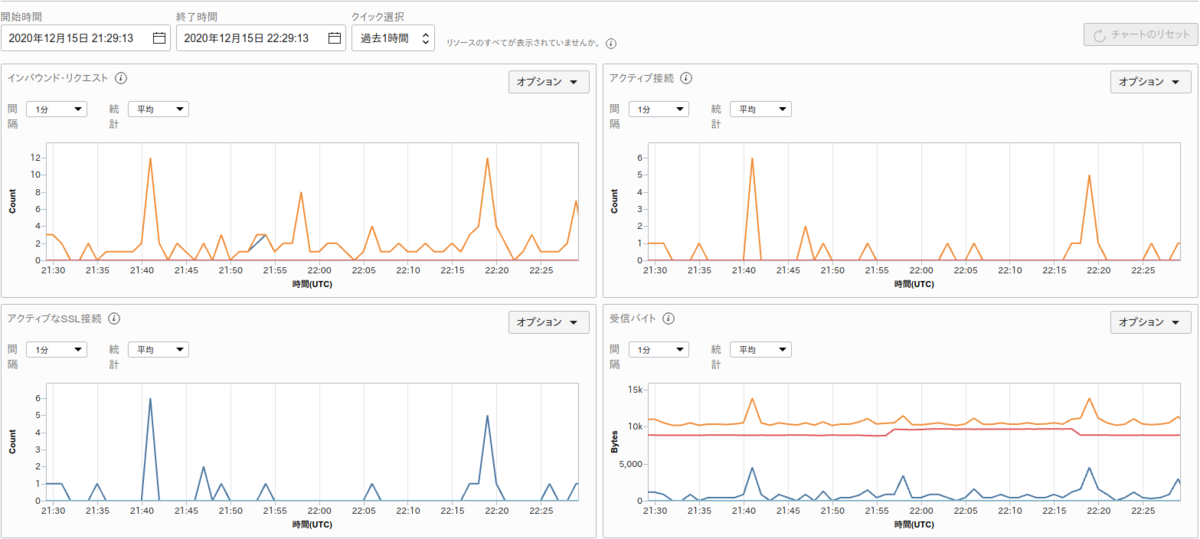
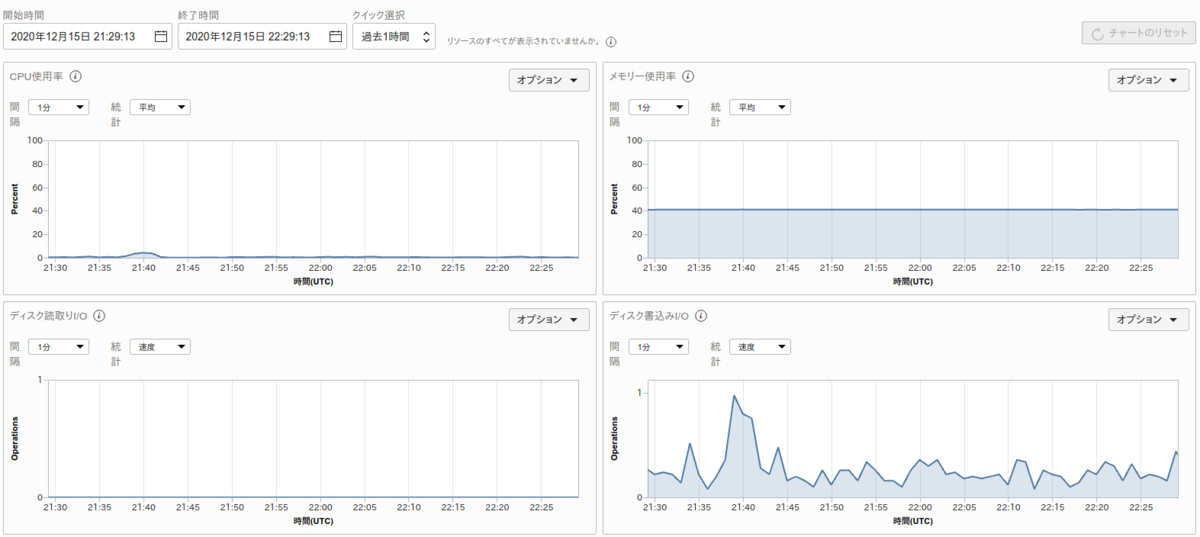
コレでも十分に綺麗なのですが
といった課題があります。
そこで LB や VM の監視には、 OSS の データ可視化ツール Grafana を使います。
Grafana を使うことで以下のようなダッシュボードを作成できます。 上段が LB で、下段が VM です。

ただし、 Grafana はデータの可視化ツールなのでそれ単体では何も監視できません。
Oracle Cloud には Monitoringサービス というのがあり、クラウドの各リソースのメトリクスを Web ブラウザや API を通じて取得することが出来ます。
今回は Grafana から Oracle Cloud の API を叩いてメトリクスを取得し、可視化します。
監視システムの構成
今回の監視システムの概要は以下のようになります。
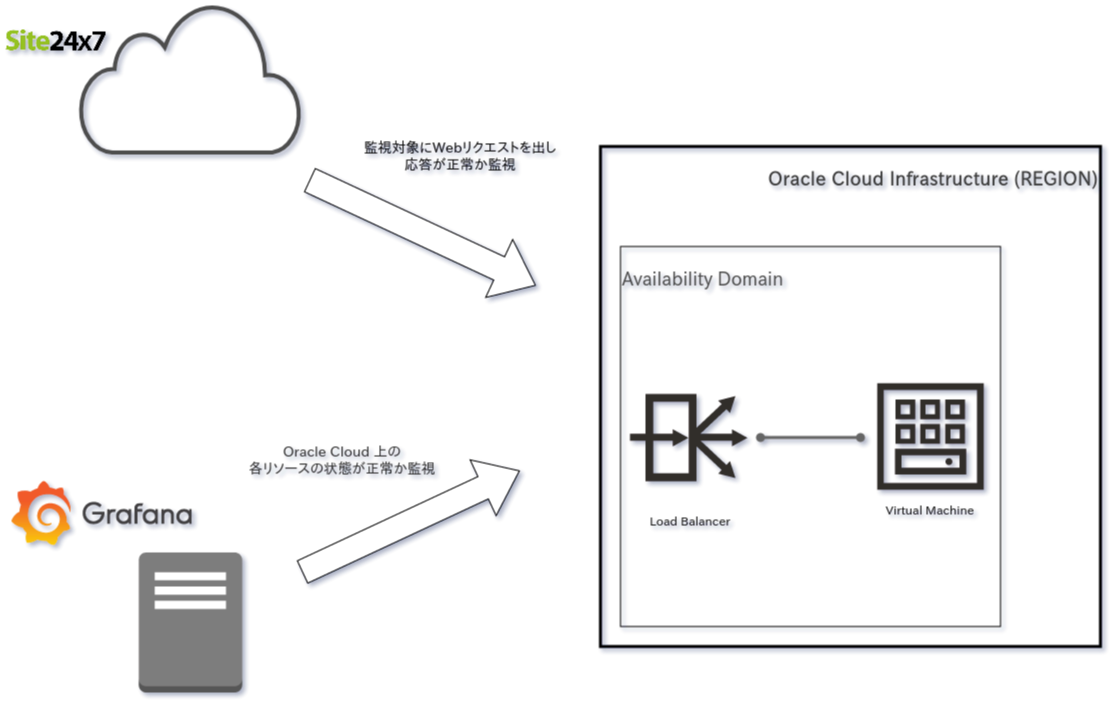
長々と書いてしまいましたが、監視対象は Oracle Cloud 上に作った 「https://headtonirvana.dev/」 という URL の Web システムで、
監視システムは
を使います。
Oracle Cloud の 外形監視 を site24x7 で実現する
それでは外形監視から始めましょう。
site24x7 にユーザ登録します。作成してもいいですし、他サービスのアカウントとも連携できます。
ログイン後は Web サイト監視の追加画面で監視したい URL を設定しましょう。 あとは基本的にデフォルトのままでいいです。

しばらく待つと監視が始まり、以下のような画面になります。とても簡単。
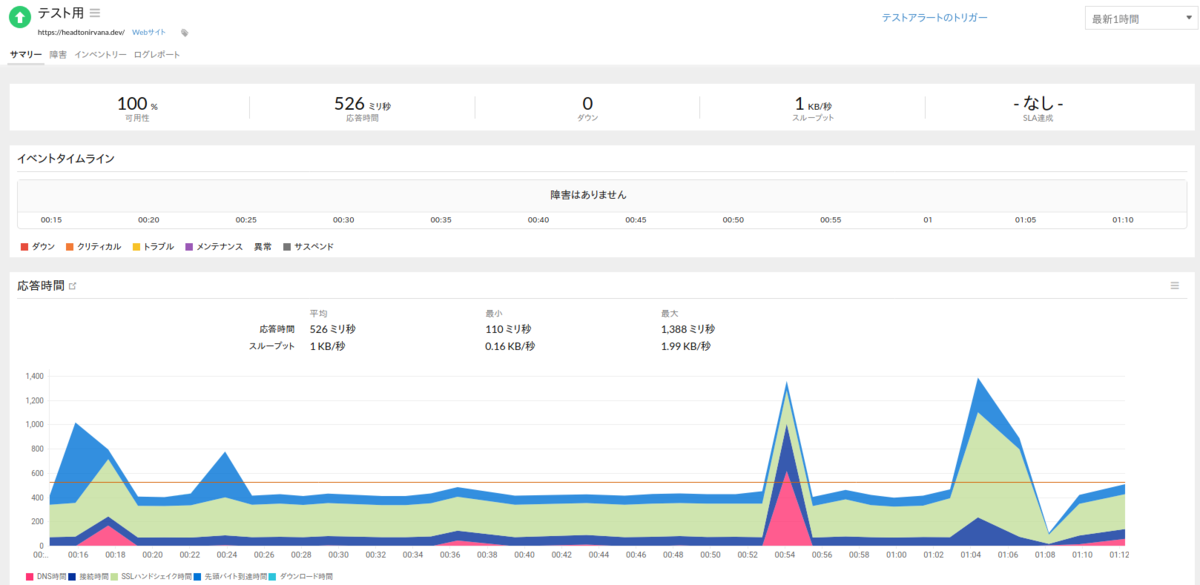
Grafana から Oracle Cloud を監視できるようにする
Grafana のインストール
今回は VM に Grafana をパッケージからインストールします。
VM の OS は Ubuntu 20.04 LTS です。
こちらの公式手順どおりに行います。
リポジトリを登録し
sudo apt-get install -y apt-transport-https sudo apt-get install -y software-properties-common wget wget -q -O - https://packages.grafana.com/gpg.key | sudo apt-key add -
インストールします
sudo apt-get update sudo apt-get install grafana
そして起動
sudo systemctl daemon-reload sudo systemctl start grafana-server sudo systemctl status grafana-server sudo systemctl enable grafana-server.service
ブラウザで <IPアドレス>:3000 にアクセスして、grafanaの画面が出れば成功です。
Grafana で監視するためのユーザとグループ作成
次は Oracle Cloud のコンソールから行います。
Grafana で OCI を監視するための専用ユーザを作ります。
このユーザを使って Grafana から各メトリクスを取得します。 システムへの変更権限は不要なので、読み取り権限だけのユーザを作成します。
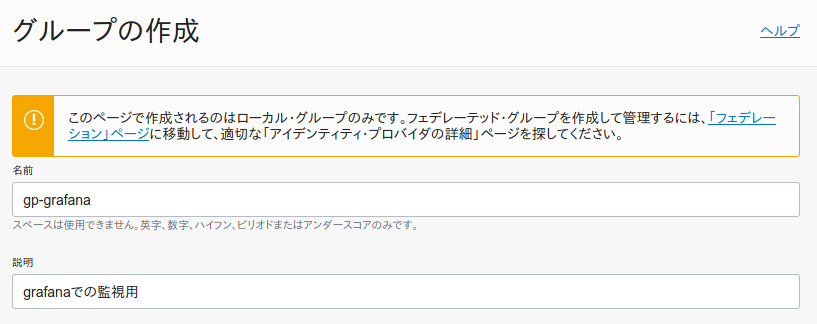
まずはグループの作成です。コンパネ画面から、「アイデンティティ」→「グループ」と進み、「グループの作成」を押下します。
今回は以下のように設定します。
- 名前:gp-grafana
- 説明: grafanaでの監視用グループ
次はグループに適用するポリシーの作成です。コンパネ画面から、「アイデンティティ」→「ポリシー」と進み、「ポリシーの作成」を押下します。
- 名前:policy-grafana
- 説明:grafanaでの監視用ポリシー
- コンパートメント:<監視対象を作成したコンパートメント>
ポリシー・ビルダーはカスタマイズ(拡張)を押下し、以下の値を入力してください。
Allow group gp-grafana to read metrics in tenancy Allow group gp-grafana to read compartments in tenancy

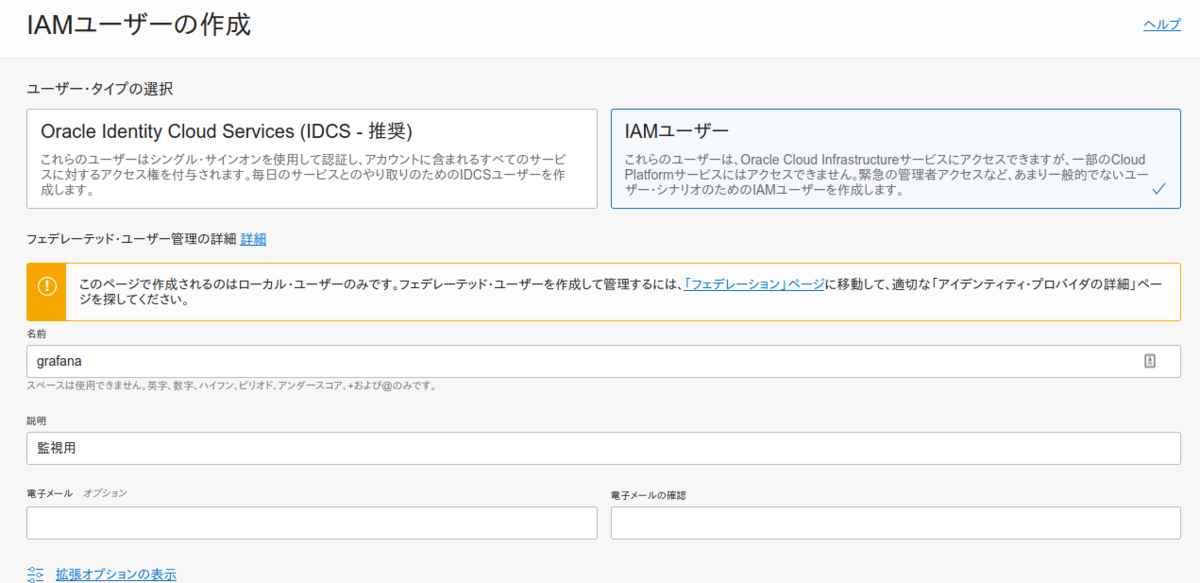
最後にコンパネ画面から、「アイデンティティ」→「ユーザ」と進み、「ユーザの作成」を押下します。
以下のように、IAM ユーザを作成します。
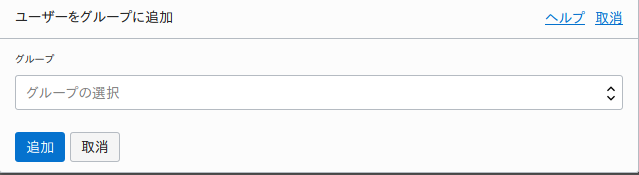
作成したユーザの詳細画面から『ユーザーをグループに追加』を押下し、先ほど作成した『gp-grafana』グループに追加しましょう。
Oracle Cloud を監視するためのプラグインを入れる
この作業は Grafana サーバで行います。
デフォの Grafana では Oracle Cloud の API を叩けないので、プラグインを入れます。
こちらのプラグインを使います
似たようなプラグインで、 Oracle Cloud Infrastructure plugin for Grafana | Grafana Labs というのがあるのですが、 こちら DEPRECATED (非推奨)になっていて、上記プラグインを使ってねと書いてあるので素直に従いましょう。 ぶっちゃけこちらのプラグインでは、現在動きません。
インストールは簡単です。以下のコマンドで簡単に入ります。
grafana-cli plugins install oci-metrics-datasource
しかし、これでおしまいではありません。 今回の監視サーバは Oracle Cloud の外部にあり、 API を叩くには認証が必要です。
認証のために、 Oracle Cloud をコマンドで操作するツール OCI CLI をインストールします。
VM に OCI CLI をインストールする
公式手順に沿って行います。
bash -c "$(curl -L https://raw.githubusercontent.com/oracle/oci-cli/master/scripts/install/install.sh)"
終わったらバージョンを確認しましょう
oci -v
次に、Oracle Cloud のコンソールから以下を確認し、メモ帳などに保存しておきましょう。
- 先程作った Grafana ユーザーのOCID
- 「アイデンティティ → ユーザー」と遷移し、ユーザの詳細画面から確認。(ocid1.user.oc1..aaaaaaa......みたいなやつがそうです)
- 接続するOracle CloudのテナントのOCID
- 「管理 → テナンシ詳細」と遷移し、て何子の詳細画面から確認(ocid1.tenancy.oc1..aaaaaaa....みたいなやつがそうです)
サーバに戻って、 OCI CLI のセットアップをしましょう。
oci setup config
選択肢は基本的にデフォで大丈夫です。 先程メモしたOCIDを間違わずに入力しましょう。
セットアップが終わったら、作成された鍵ファイルの中身をメモ帳にコピーしておいてください。
cat ~/.oci/oci_api_key.pem
次は Oracle Cloud のコンソールに先程メモした鍵を登録します。
「アイデンティティ → ユーザー → APIキー」と遷移し、ユーザの詳細画面の 「APIキーの追加」を押下し、先程メモしたキーの中身を貼り付けます。

無事に保存できたら VM に戻ります。もう少しですよ!
以下のようにコマンドでリージョンの一覧が出たら CLI のセットアップは成功です。
$ oci iam region list --output table +-----+----------------+ | key | name | +-----+----------------+ | AMS | eu-amsterdam-1 | | BOM | ap-mumbai-1 | | CWL | uk-cardiff-1 | | DXB | me-dubai-1 | | FRA | eu-frankfurt-1 | | GRU | sa-saopaulo-1 | | HYD | ap-hyderabad-1 | | IAD | us-ashburn-1 | | ICN | ap-seoul-1 | | JED | me-jeddah-1 | | KIX | ap-osaka-1 | | LHR | uk-london-1 | | MEL | ap-melbourne-1 | | NRT | ap-tokyo-1 | | PHX | us-phoenix-1 | | SCL | sa-santiago-1 | | SJC | us-sanjose-1 | | SYD | ap-sydney-1 | | YNY | ap-chuncheon-1 | | YUL | ca-montreal-1 | | YYZ | ca-toronto-1 | | ZRH | eu-zurich-1 | +-----+----------------+
プラグインが Oracle Cloud の API を使えるようにする
最後の手順です。 Grafana が Oracle Cloud の API を使えるようにしましょう。
セットアップした設定を grafana ユーザも使えるようにします。
sudo cp -r .oci /usr/share/grafana sudo chown -R grafana:grafana /usr/share/grafana
次に config を編集し、key ファイルの PATH を変更します。
sudo vim /usr/share/grafana/.oci/config
以下のようにしましょう。
key_file=/usr/share/grafana/.oci/oci_api_key.pem
ここまで出来たら、 Grafana の UI にログインしましょう。
Configration → Data Sources と遷移し

Add data source を押下し
下の方にある、Oracle Cloud Infrastructure Metrics を Select します。

設定画面で、先ほどコピーしておいたテナントの OCID を設定し、リージョンは監視対象を作成したリージョン(私はap-tokyo-1)、environment は local で大丈夫です。

そして左下の Save & Test を押下し、以下のように 「Data source is working」と表示されれば成功です!

失敗しちゃう場合はコピーしたファイルのパーミッションや鍵の場所などを確認してください。
やっとダッシュボード作れますよ奥さん!
Grafana でダッシュボードを作る
コレで準備完了!実用的で格好いいダッシュボード作りましょう!
先程は
しかし今回の構成で言うと、LB を監視することで
- 実際にどのくらいのアクセスが来てるのか
- 来たアクセスを正常に、遅滞なく処理できているか
ということを確認でき、さらに VM を監視することで
- システムリソースを使い切っていないか
- サーバの I/O が処理待ちになっていないか を確認することが出来ます。
と書きましたが、もうちょっと具体的に話しましょう。
RED Method と USE Method という考え方があります。
RED Method と USE Method
まず RED Method は
の頭文字をとったもので、
上記の記事では
サービスに関わる誰もがエラー率、リクエスト率、そしてそれらのリクエストのレイテンシの分布を理解する必要があります。 サービス監視の観点に一貫性を持たすことができ、開発側が意図していないコードのへの問い合わせも行えます。 RED Method はユーザの満足度を示す優れた指標です。 エラー率が高い場合、それは基本的にユーザーに影響があり、ページ読み込みエラーが発生します。 表示時間が長いとWebサイトの表示が遅くなります。これらは、意味のあるアラートを作成し、SLA を測定するための優れた測定基準です。
と紹介されてます。
そしてさらにオライリーが出版している『入門 監視』には、監視のデザインパターンとして以下のような考え方が紹介されています。
まず監視を追加すべきなのは、ユーザがあなたのアプリケーションとやり取りをするところです。 Apache のノードが何台動いているか、ジョブに対していくつのワーカが使用可能かが使用可能と行ったアプリケーションの実装の詳細をユーザは気にしません。
最も効果的な監視ができる方法の一つが、シンプルに HTTP レスポンスコード(特に HTTP 5xx 番台)を使うことです。 その次として、リクエスト時間(レイテンシとも言う)も有益です。 このどちらも『何が』問題なのかは教えてくれませんが、『何かが』問題で、それがユーザに影響を与えていることは分かります。
とあります。
RED Method はユーザに何が起きているのかを監視するために有益な、監視の指標だということが分かります。
次に USE Method は
- Utilization (リソースがどのくらいビジーだったかの割合)
- Saturation (キューの長さなどの、各リソースの仕事量)
- Errors (エラーイベントが起きた数。messageログなど)
の頭文字で、リソース内部の状況を把握するのに適しています。
なので今回は、ユーザに近い LB を Red Method で監視し、 VM を USE Method で監視します。
そうすることで、例えばアクセスが急増した時に LB のリクエスト数と VM の CPU 使用率の相関を確認でき、 障害原因の調査や今後のリソース増強へのヒントに使うことが出来ます。
Oracle Cloud の LB を Red Method で監視する
公開されている LB のメトリクス情報を元に、どのメトリクスを監視するか考えてみましょう。
それぞれ、以下のメトリクスで良さそうです。
- Rate (単位時間あたりのリクエストの数)
- HttpRequests
- Errors (その中でのエラーの数)
- HttpResponses502
- HttpResponses504
- HttpResponses5xx
- Duration (リクエストをさばくのにかかってる時間)
- ResponseTimeHttpHeader
それでは作っていきましょう!
Create → Dashboard と進みます
ダッシュボード作成画面になるので、 「Add new panel」を押しましょう
これが panel の作成画面です。ここでクエリを作成してグラフを作っていきましょう。
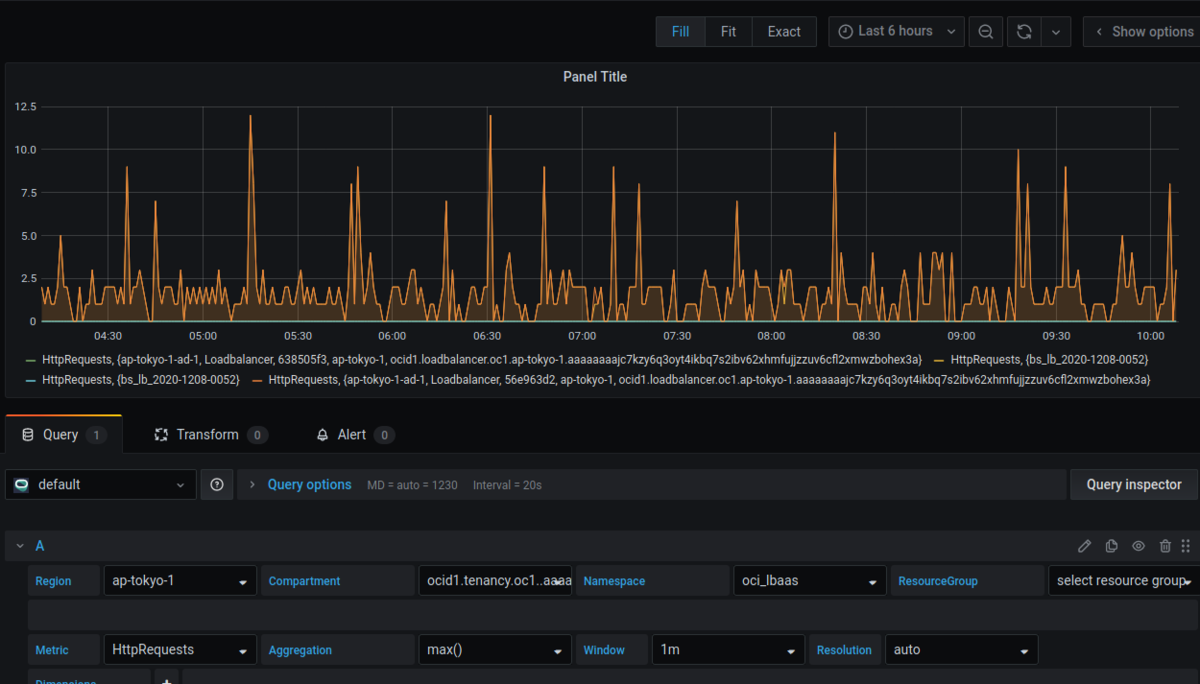
まずは HttpRequests です。単位時間あたりのリクエスト数を可視化しましょう。
以下のように設定すると、グラフが出てくるはずです。
| 項目 | 設定値 |
|---|---|
| Region | <監視対象があるリージョン> |
| Compartment | <監視対象があるコンパートメント> |
| Namespace | oci_lbaas |
| Resourcegroup | NoResourceGroup |
| Metric | HttpRequests |
| Aggregation | max() |
| Window | 1m |
| Resolution | auto |
Panel の名前はわかりやすくし、 Description の部分には監視しているメトリクスの説明を入れると忘れた頃に見ても安心です。
あとは Save を押してダッシュボードの名前を設定してみましょう
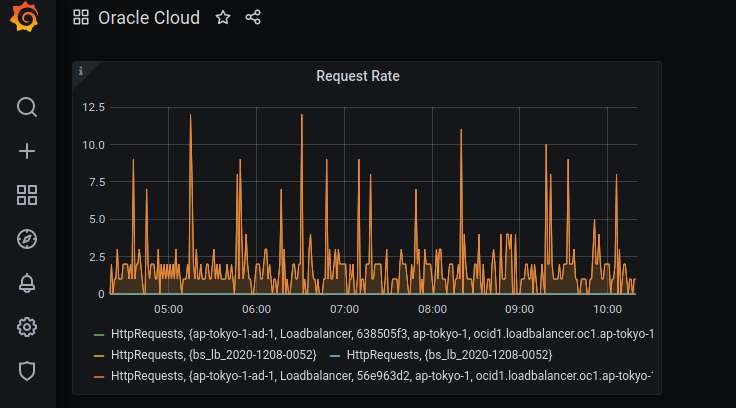
4つのメトリクスが出てきてると思いますが、これはロードバランサ自体と、バックエンド・セットというバックエンドのサーバへのヘルスチェックなどを定義した論理エンティティのメトリクスが表示されています。 そして、Oracle Cloud の LB はデフォルトで冗長化されてるので4つのメトリクスが表示されているというわけです。
次はエラーの数です。まずグラフの種類は 「Stat」を選択しましょう。
Display の Calculation は Max にしておいて下さい

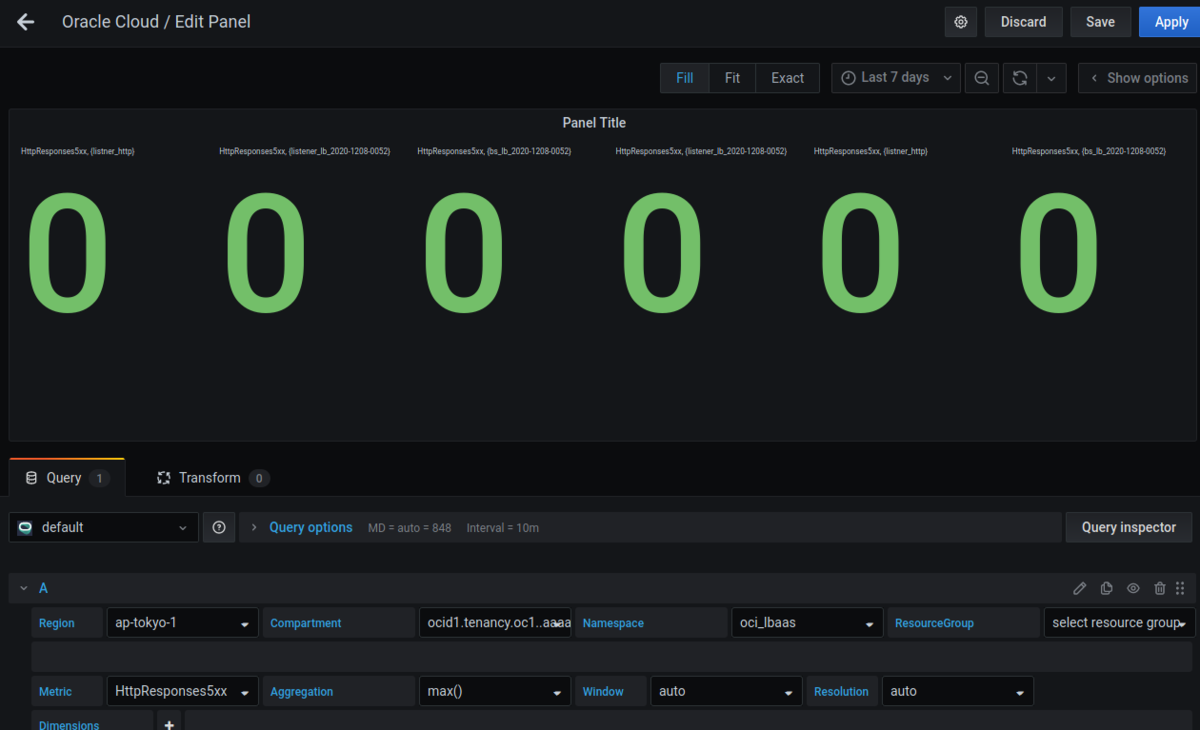
そして以下のように設定すると、
| 項目 | 設定値 |
|---|---|
| Region | <監視対象があるリージョン> |
| Compartment | <監視対象があるコンパートメント> |
| Namespace | oci_lbaas |
| Resourcegroup | NoResourceGroup |
| Metric | HttpResponse502 |
| Aggregation | max() |
| Window | 1m |
| Resolution | auto |
こんな画面が出てくると思います。6個もあるのは
- LB の http リスナー
- LB の https リスナー
- バックエンド・セットの リスナー
が冗長化されてるからです。
コレ以外にも504エラーの数もみたいので、クエリを複製してちょっと中身を変えましょう。
クエリの右上の部分に Duplicate query ボタンがあるので押してみましょう
クエリが複製されるので、合計2つ作って
- HttpResponse502
- HttpResponse504
それぞれが表示されるようにしてみましょう
複製したクエリの、以下の部分を変更しましょう
| 項目 | 設定値 |
|---|---|
| Metric | HttpResponse504 |
こんな画面ができしましたか?

「表示がちょっと多いな」と感じた方は、 Dimensions でコンポーネントをフィルタリングしてみましょう。
次は処理にかかった時間 Duration ですね。
以下のようにクエリを作りましょう。
| 項目 | 設定値 |
|---|---|
| Region | <監視対象があるリージョン> |
| Compartment | <監視対象があるコンパートメント> |
| Namespace | oci_lbaas |
| Resourcegroup | NoResourceGroup |
| Metric | ResponseTimeHttpHeader |
| Aggregation | max() |
| Window | 1m |
| Resolution | auto |

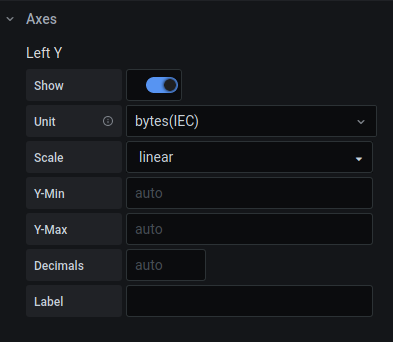
時間がわかりやすいように、縦軸に単位を付けましょう
オプションの Axes → Left Y → Unit で milliseconds(ms) を選択します。
あとはタイトルと説明を書いて保存
ダッシュボードに戻って、画面に収まるようにグラフの幅を調整しましょう。
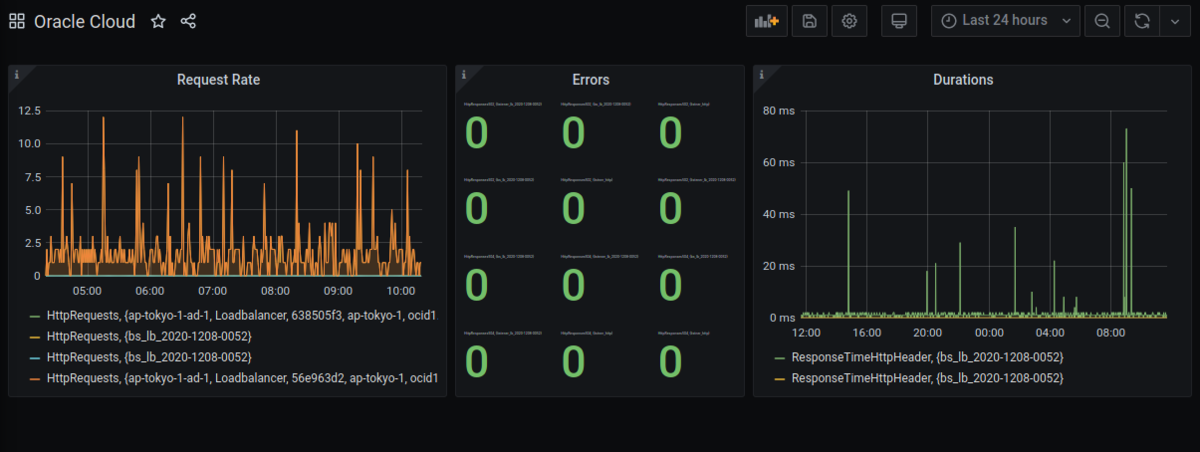
コレで Red Method の完成です!
Oracle Cloud の VM を USE Method で監視する
公開されている VM のメトリクス情報を元に、どのメトリクスを監視するか考えてみましょう。
それぞれ、以下のメトリクスで良さそうです。 今回の構成では、messageログの監視といった方法を使ったエラーイベントが検知できないので Error は見ません。
- Utilization (リソースがどのくらいビジーだったかの割合)
- CpuUtilization
- MemoryUtilization
- Saturation (キューの長さなどの、各リソースの仕事量)
- NetworksBytesIn
- NetworksBytesOut
それでは先程の要領でグラフを作ってみましょう。
Namespace と Metric が変わってることに注意です。
- CpuUtilization
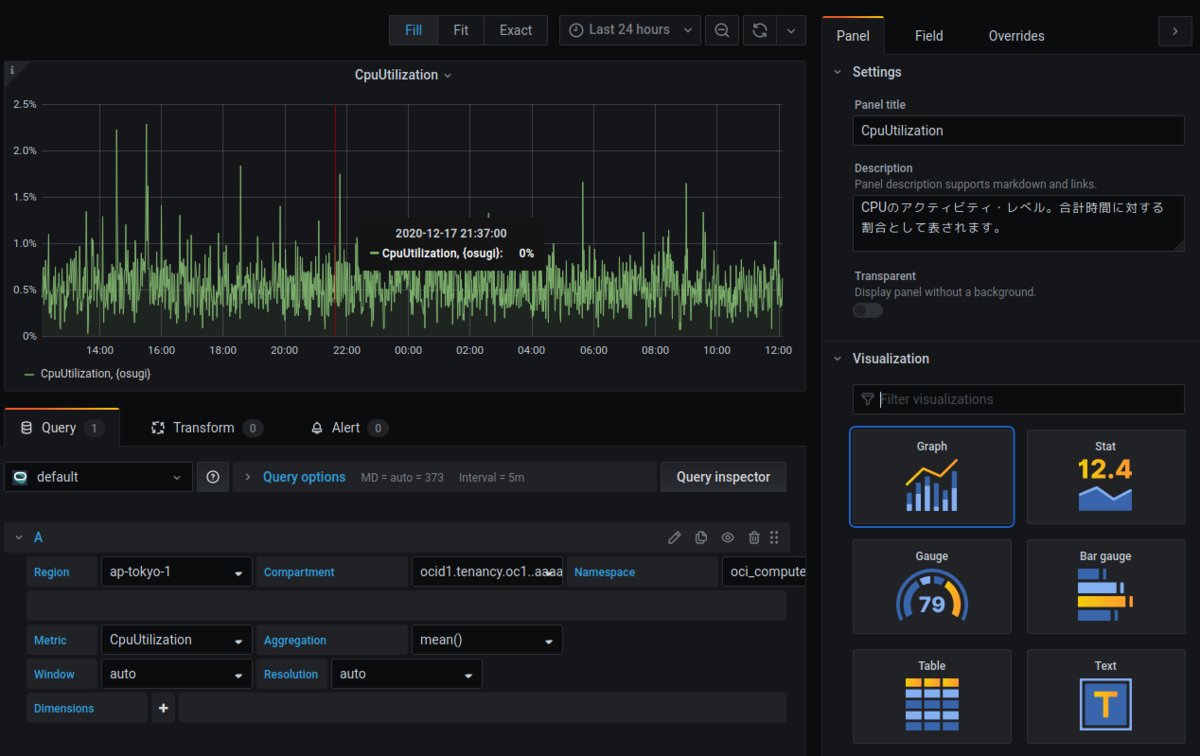
| 項目 | 設定値 |
|---|---|
| Region | <監視対象があるリージョン> |
| Compartment | <監視対象があるコンパートメント> |
| Namespace | oci_computeagent |
| Resourcegroup | NoResourceGroup |
| Metric | CpuUtilization |
| Aggregation | max() |
| Window | 1m |
| Resolution | auto |
- MemoryUtilization
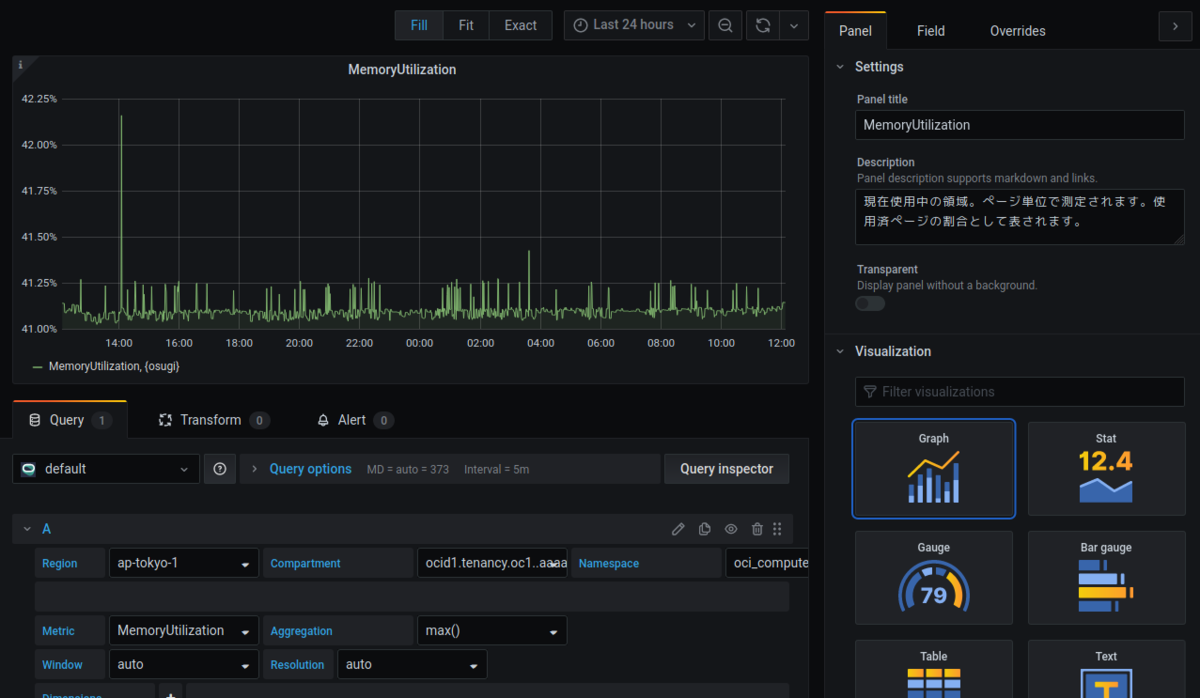
| 項目 | 設定値 |
|---|---|
| Region | <監視対象があるリージョン> |
| Compartment | <監視対象があるコンパートメント> |
| Namespace | oci_computeagent |
| Resourcegroup | NoResourceGroup |
| Metric | MemoryUtilization |
| Aggregation | max() |
| Window | 1m |
| Resolution | auto |
- NetworksBytesIn/Out

Aggregation が rate になっていることに注意して下さい
| 項目 | 設定値 |
|---|---|
| Region | <監視対象があるリージョン> |
| Compartment | <監視対象があるコンパートメント> |
| Namespace | oci_computeagent |
| Resourcegroup | NoResourceGroup |
| Metric | NetworksBytesIn |
| Aggregation | rate() |
| Window | 1m |
| Resolution | auto |
| 項目 | 設定値 |
|---|---|
| Region | <監視対象があるリージョン> |
| Compartment | <監視対象があるコンパートメント> |
| Namespace | oci_computeagent |
| Resourcegroup | NoResourceGroup |
| Metric | NetworksBytesOut |
| Aggregation | rate() |
| Window | 1m |
| Resolution | auto |
またネットワークのグラフは受信と送信が混ざらないように、送信のグラフを反転させてます。
やり方は以下のように、 Out という文字列のあるメトリクスデータをY軸反転させます。
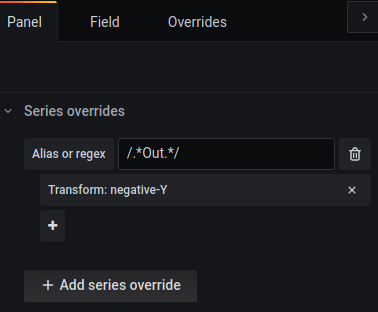
あとは単位もつけてあげましょう
あとはダッシュボードに戻って大きさを揃えて出来上がりです。
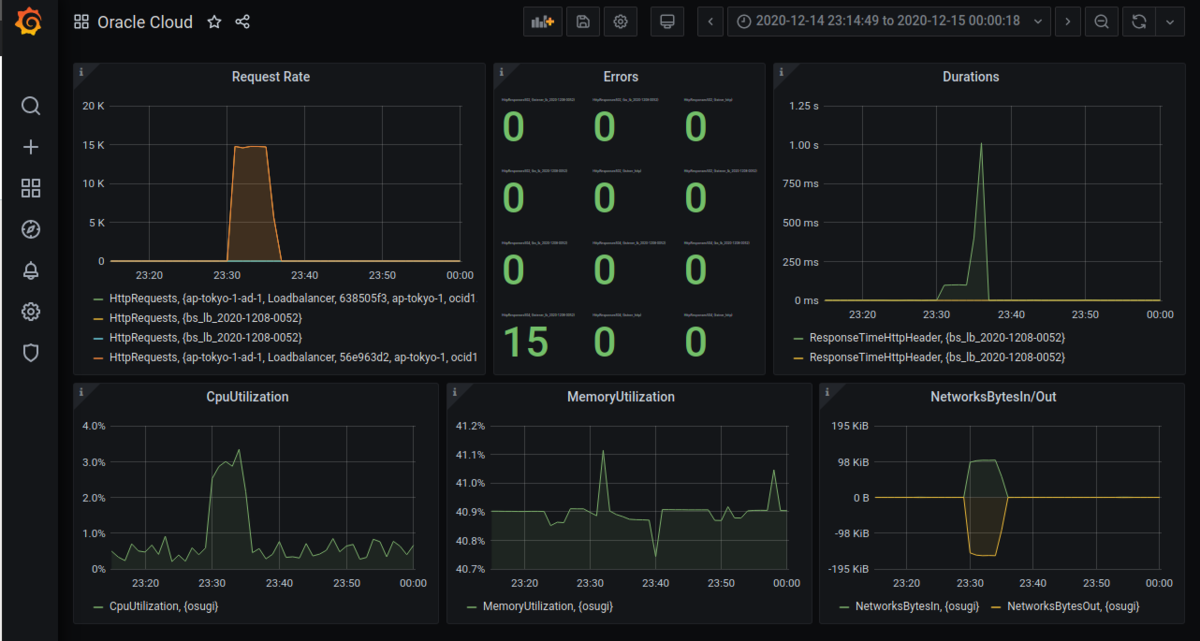
ダッシュボード設定
ダッシュボード上部から、ダッシュボードのセッティングを行えます。

名前とかタグの設定ができるんですけど、今回お伝えしたいのが Graph Tooltip です。
- Default
- Shared crosshair
- Shared Tooltip
から選べるんですが、この設定で各パネルにある値を関連付けて確認しやすくなります。
画面で比較してみましょう
- Default だと、マウスオーバーで1つのパネル上の値を確認できます
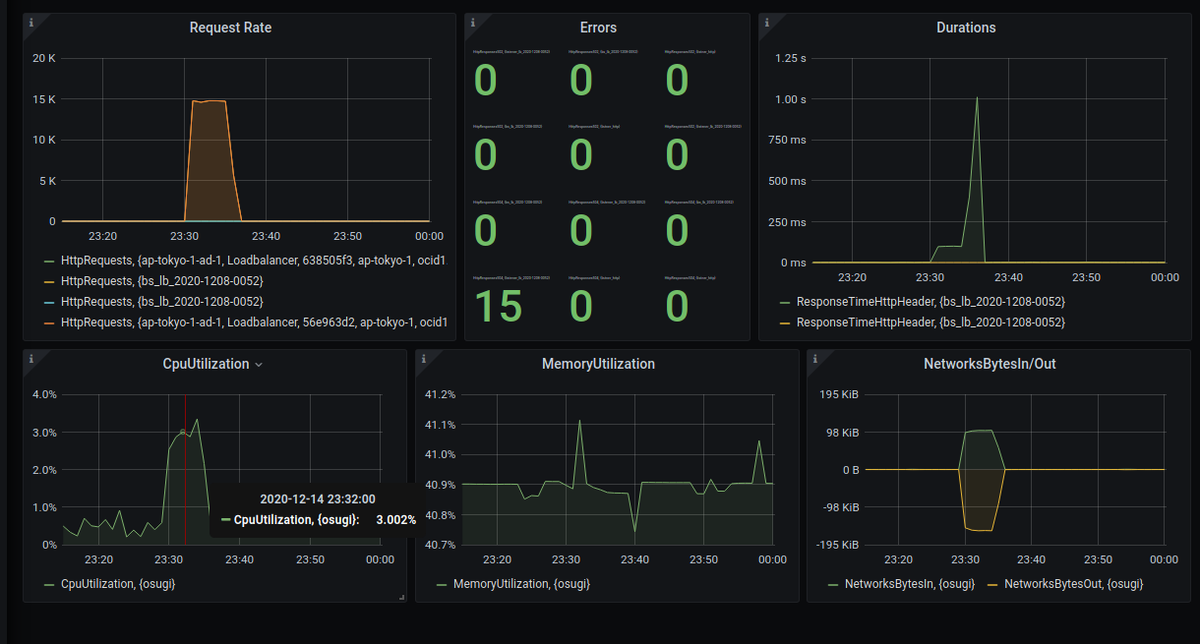
- Shared crosshair だと、時間軸を赤い棒が各パネルに表示されます
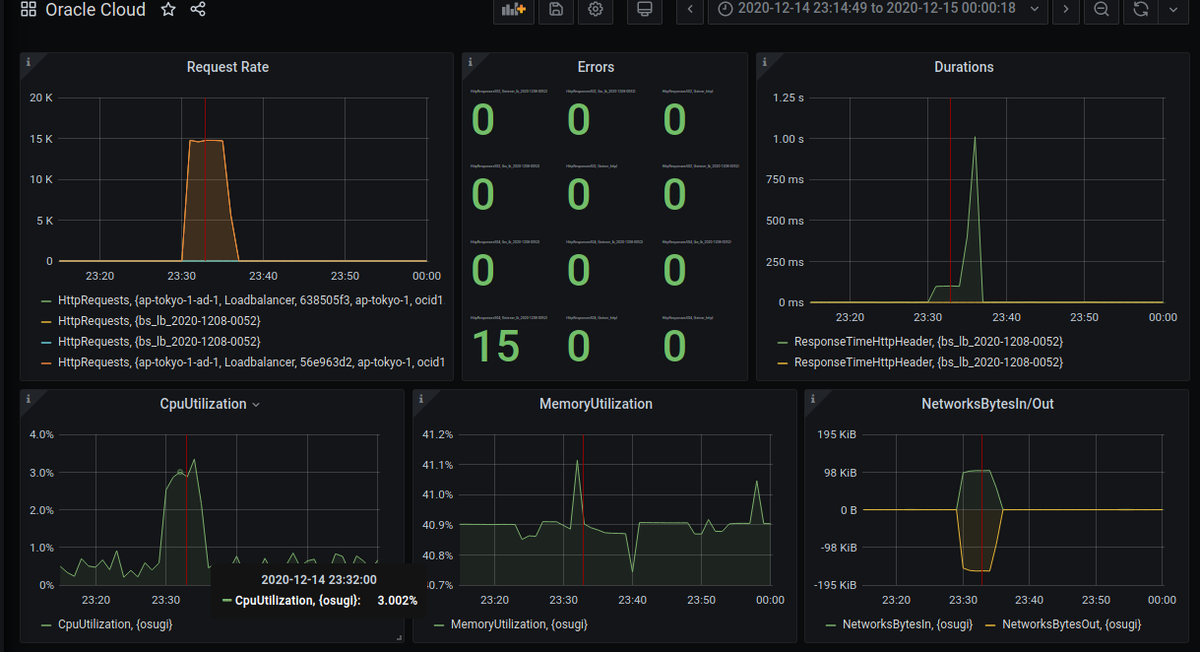
- Shared Tooltip だと、時間軸を赤い棒と、そのときの値が各パネルに表示されます
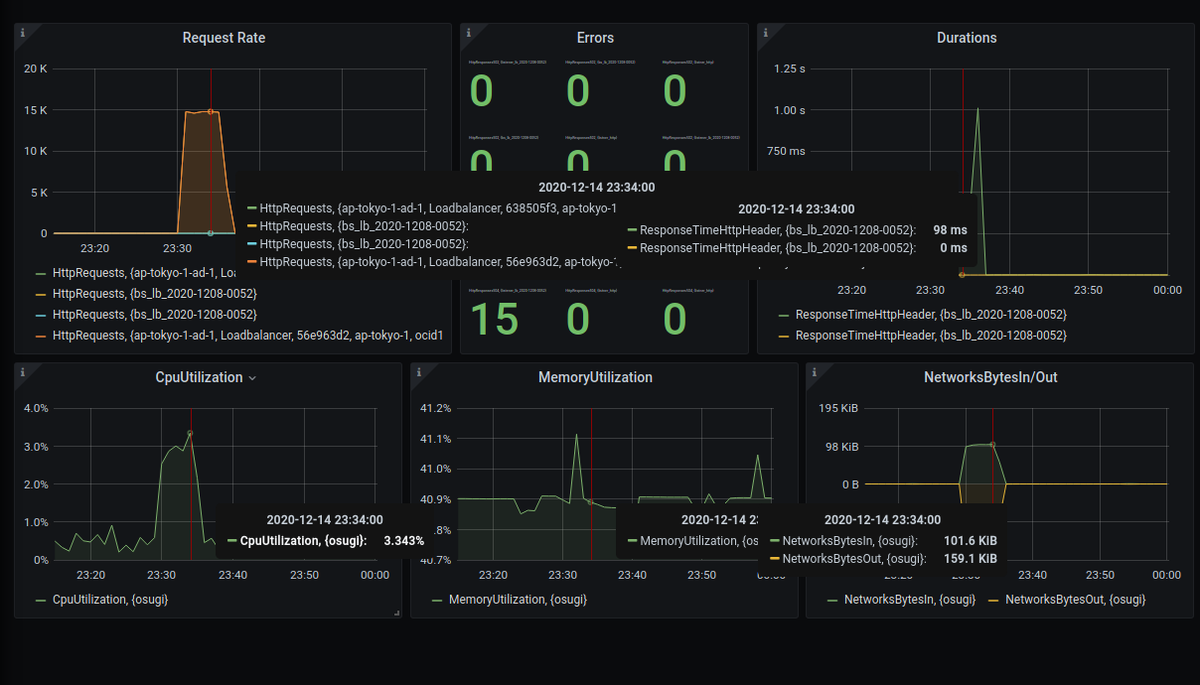
違いが分かりましたでしょうか?
個人的に好きなのは Shared crosshair です。「この時にはアクセスが多くて、CPU使用率も高かったんだな」ていうのが直感的に分かって、 Shared Tooltip だと画面の情報がちょっと多い感じがするので。
こういうダッシュボードを定期的に共有して、「アクセスが多い時にサーバのリソースを使い切ってるのでサーバを増やしましょう」とか「このままユーザ数が増えていくとリソース不足が懸念されるので、来季の予算増やしましょう」みたいな話ができるようになると思います。
まとめ
クラウドの登場を期に SRE や DevOps、 SLA 、 SLO などの用語や概念が広まったり生まれたりして、運用界隈は新しい情報が多いです。
その中でも私が好きな言葉に「Nines don’t matter if users aren’t happy.(数字の9をいくら並べても、ユーザがハッピーじゃなきゃ意味ないよ)」というのがあります。
この辺の記事が原点ぽい?
T シャツなんかも売ってます。
T シャツの話はよくて、その記事の中ではシステム稼働率とかで9の数字をいくら並べても不幸な目に合うユーザは居るわけで、ユーザのために本当に必要なものを見極めて優先度を付けて監視しましょう。 絶対に気にしないとダメなものを定義しましょう。
みたいなことが書いてあります。
クラウド、仮想化、コンテナ化で抽象度のレイヤは高度かつ複雑になってきました。今回の構成でも、見ようと思えば紹介した量の何倍もの情報を見ることができるわけで、監視の重要性とは裏腹に「何したら良いの?」と戸惑う方も多いのではないのでしょうか。
今回紹介したような RED/USE Method のような考え方で優先度を付けて監視できると、幸せなユーザが増えるかもしれませんね。
最後までお読み頂きありがとうございました。
明日の 12月19日は Naotaka Shinogi さんです。よろしくおねがいします!